This section takes about 30 minutes to complete.

UDFs (Bonus)
What's missing?

Short Answer:
- Pandas UDFs (Vectorised UDFs)
Python UDFs
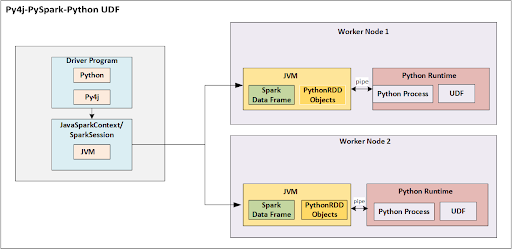
How can I bring in my own custom Python logic?
(needs other libraries, not available as pyspark built-in functions)
Basic Answer: Python UDFs
How does this work?
- JVM serializes data and sends it to the Python process
- Python process deserializes, then serializes it back to the JVM
- JVM deserializes the data for running next operations/steps
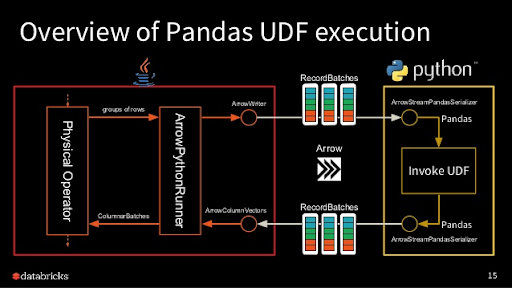
But..how can we be more efficient when switching between the JVM and Python??
Basic Answer: Vectorization
How does this work? (the Apache Arrow project is basically dedicated to this!)
- Batches/chunks of a single/multiple column(s) are serialized compactly/efficiently then sent to the Python process
- Which Python library is really good at vectorized operations on data again?
- Pandas! uses NumPy (written in C) under the hood
- Chunks of data are serialized then finally sent back to the JVM
A pandas user-defined function (UDF)—also known as vectorized UDF—is a user-defined function that uses Apache Arrow to transfer data and pandas to work with the data. pandas UDFs allow vectorized operations that can increase performance up to 100x compared to row-at-a-time Python UDFs. (Reference)
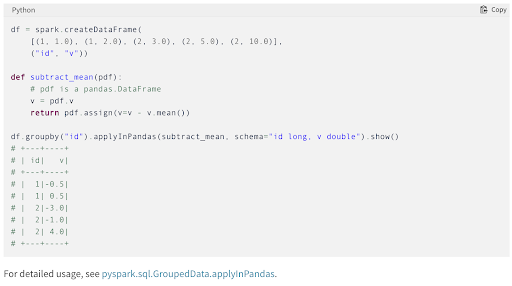
This even allows you to run custom logic per each group of data in a distributed manner:
Pandas DataFrame IN Pandas DataFrame OUT This is massive.
Wowww, how do I actually use Pandas UDFs then?
Basic Answer: Learn the different types of Pandas UDFs AND Pandas Functions APIs
- Example blog post (potentially outdated)
- Series to Series (these can often directly replace your Python UDFs)
- Grouped Map (Pandas Functions APIs)
- This is THE holy grail, you can parallelize data processing by treating each “group” as an independent Pandas DataFrame
Try it yourself (optional)
Import the following Pandas UDF benchmark notebook into Databricks using the URL method:
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/1281142885375883/2174302049319883/7729323681064935/latest.html?_gl=1*1dt6rri*_gcl_aw*R0NMLjE2NTgwNTYzNjguRUFJYUlRb2JDaE1JME1mR24tWF8tQUlWVHRrUkNCMHdqd05IRUFFWUFTQUFFZ0pJM3ZEX0J3RQ..&_ga=2.69934608.18112261.1660751261-1602603096.1651760939&_gac=1.262850872.1658056369.EAIaIQobChMI0MfGn-X_-AIVTtkRCB0wjwNHEAEYASAAEgJI3vD_BwE
A Deeper Reference
Check out O'Reilly's "Learning Spark" book