This section takes about 20 minutes to complete.

Exercise: Create a Workflow
Quite often, when transforming data, there are several stages of transformation, which when run one after another form what we call a "Data Pipeline" or a "Workflow". For example, a Workflow can start with an ingestion job, then feature several transformations that can fan-out and then fan-in. These Workflows can become rather complex in nature, and it leaves room for human error when individual steps are triggered manually or variability in a large team. In order to encourage reproducibility, it is encouraged to use a Workflow or Data Pipelining tool, in which individual jobs and its properties (like dependencies from which to trigger) are defined. These dependencies are often represented by a DAG (Directed acyclic graph). There are a variety of Workflow/Data Pipelining tools that exist such as Dagster, Airflow, and other Platform- or Cloud-native offerings.
Coming back to our existing Batch use case, workflows for Batch Transformations are often started with a manual trigger or automatically in response to an event or cron schedule. In this exercise, we will create a Workflow in Databricks to trigger first our Bronze transformation, and upon success, trigger the Silver transformation logic.
In the left-navigation window in Databricks, open Workflows
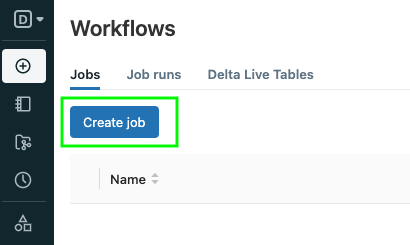
Next, click Create Job
Enter a name for the task that will run your Bronze logic and choose the type Notebook.

Note that there are a variety of logic types to choose from aside from Notebook. In more production settings, we might opt to package our logic in a jar or Python Wheel. In this case, we're using the logic created in Notebooks in earlier exercises.
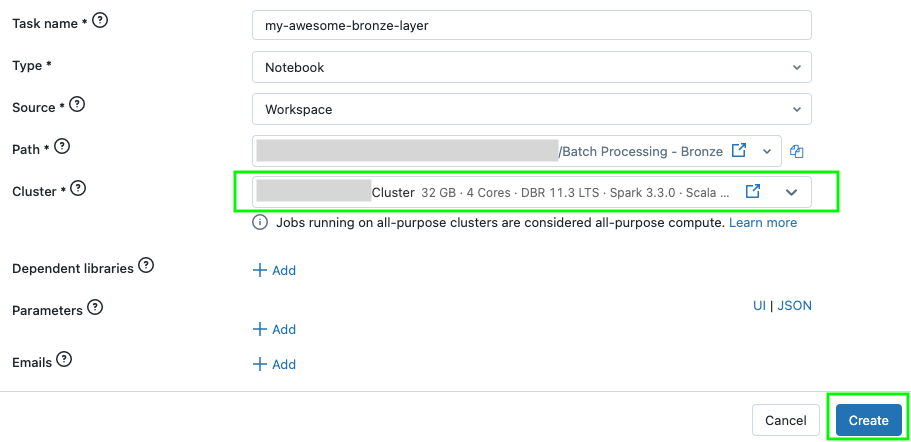
Next, for the Path field, choose the Batch Processing - Bronze Notebook from your Workspace:

For the Cluster field, choose your Cluster. Click Save.
Click the big + button to create your next task (for the Silver logic) and select Notebook
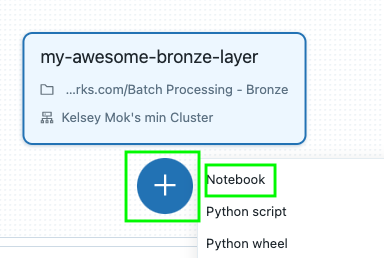
Repeat the same steps as earlier but name this task uniquely (to represent the Silver logic). Note that there is now a dependency on the Bronze task. Click Create Task
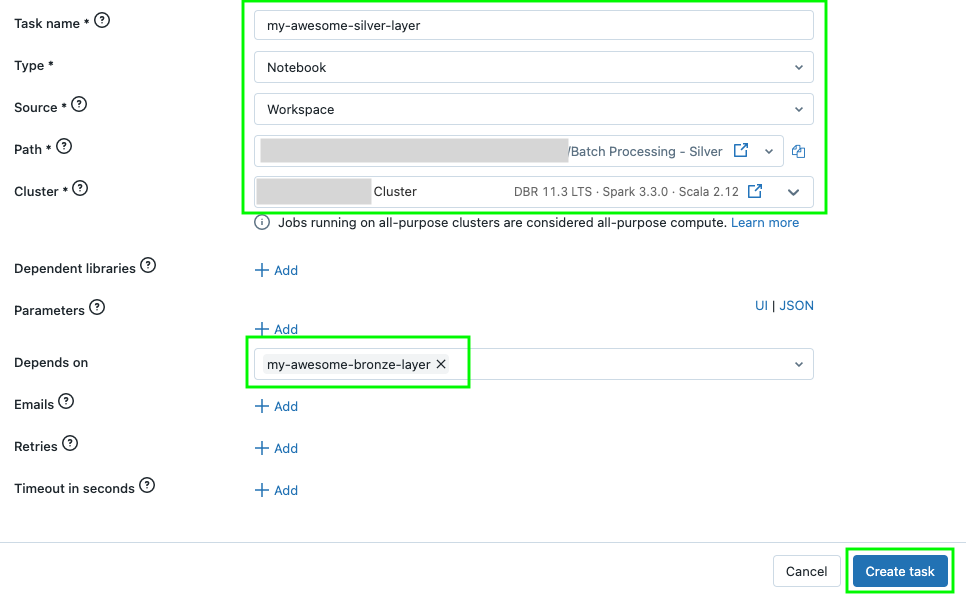
Click the big + button to create your next task (for the Gold logic) and select Notebook
Repeat the same steps as earlier but name this task uniquely (to represent the Gold logic). Note that there is now a dependency on the Silver task. Click Create Task
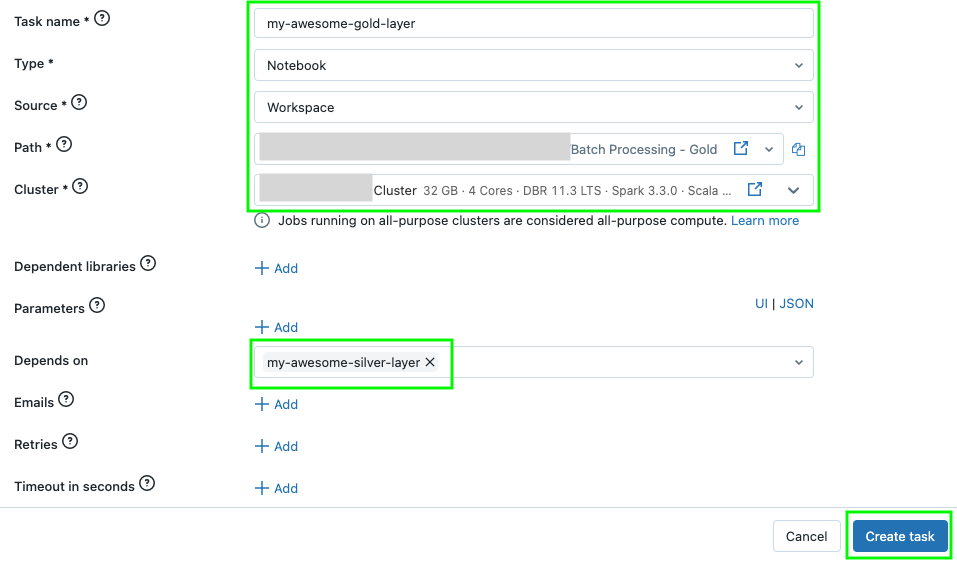
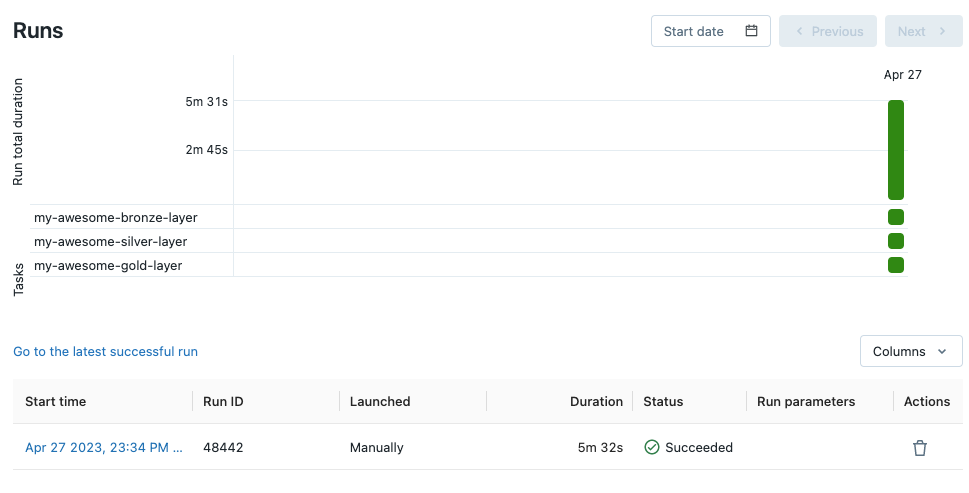
Click the Runs tab at the top left and click "Run now" to trigger your job. If your cluster is not already running, it probably will take a while.
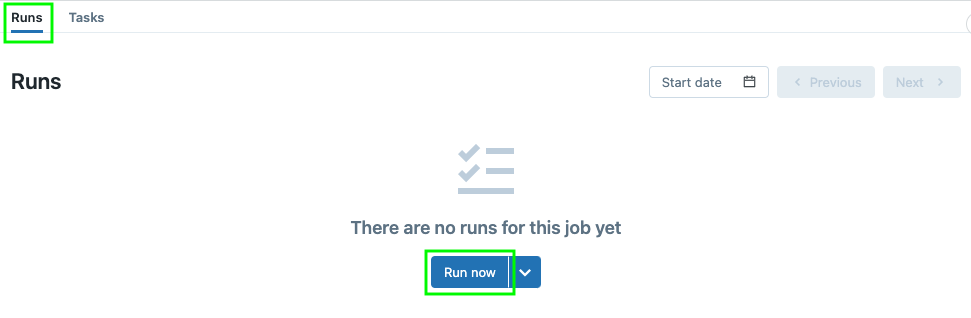
Success!
Reflect
What are some drawbacks of our notebooks that might affect pipeline processing time?
Our notebooks deliberately and by design contain tests to enhance the learning experience. In a production setting, the functions that have been written might be pulled out to a single file and packaged into a jar or Python wheel without the tests.
How can I avoid using the UI to create these Workflow tasks?
Databricks jobs can be written in declarative form through tools like Terraform.