This section takes about 20 minutes to complete.

Spark Workflow and Partitioning
Optimisation
At this point, we've wrangled/transformed our data...but how do we actually optimize our job’s performance? Golden Rule: In the real world, make sure your dataset/table is partitioned well.
- Lots of small files are the enemy!
- Having lots of tiny files will result in S3 needing to do lots of file listing operations. These are extremely slow and can even be expensive
- Lots of small files means lots of data shuffling through the network. This is slow!
- HUGE files are also bad
- Having too few files (all being huge) means you probably won’t take advantage of all of the cores in your cluster. In other words, the data can’t be easily distributed around the cluster
- Each node in your cluster might even have to try and break down each of these huge files in order to redistribute some data to other nodes. This is a waste of time and money (to emphasise the point).
So what’s a suitable strategy?
- There’s no "best" number. In parquet, try to target each
.snappy.parquetfile to be somewhere roughly between 256MB to 1GB - More importantly, make sure that you’re partitioning on columns that you frequently filter or do groupBy on (another reason to be Product-minded and ask your consumers what kinds of questions they'll need answered by your data)
- DO NOT partition on columns with high cardinality (e.g. a userId, which has millions of distinct values) this will result in lots of small files and lots of file listing operations
Partitioning
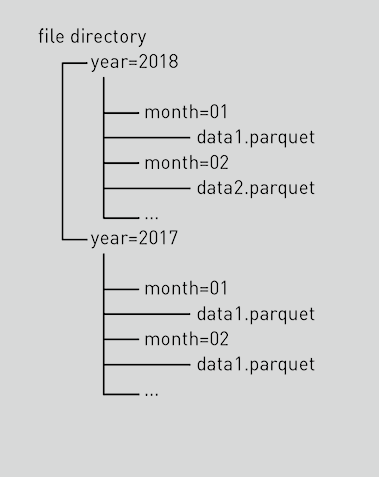
Partitioning strategy is the most important decision we have to get right!
If your partitioning strategy is decent, you’ll most likely be fine and won’t need to tweak other knobs. Especially going forward in the future with Spark 3.0’s Adaptive Query Execution (AQE), a lot of optimizations will be automated for you!
So how does a partitioned table look?
- It would actually look like a bunch of hierarchical folders
- The partitioning values become their own folder (e.g. year=2018)
- The underlying data will be at the bottom of the hierarchy and will
- often have a
.snappy.parquetfile extension (if using Spark and Parquet)
Can you give me an example?
- Partitioning the table based on some notion of time is a popular option
(check if that makes sense for your consumers and your use case though!)
- e.g. assuming each day of data for the table is of the order of 128MB - 1GB, then your partitioning keys can be (“year”, “month”, “day”)
- You don’t need to explicitly define all the values, Spark will smartly create a new partition for each distinct combination of your partitioning values
Working with Partitioned Data
Partitioning FAQs
So...is a parquet file a file or a folder of files?
- With a single-node library like Pandas, you can write a single
.snappy.parquetfile if you want - In the real-world they are often folders of partitions
- This way you can read/write an entire table with just one path (the root of the table)
- e.g.
s3://my-bucket/my-table/ors3://my-bucket/my-table.parquet/(both of these styles are still folders) - Underneath all the partitioning folders, you will find
.snappy.parquetfiles
- e.g.
- The query engine (e.g. Spark or Presto) will then take care of understanding the partitioning structure of the table and will optimize your queries around that
- Spark will always write the output of a DataFrame as a folder at the root level rather than a single file (because it’s designed for distributed/concurrent reading/writing of data, which often involves multiple files)
- This way you can read/write an entire table with just one path (the root of the table)
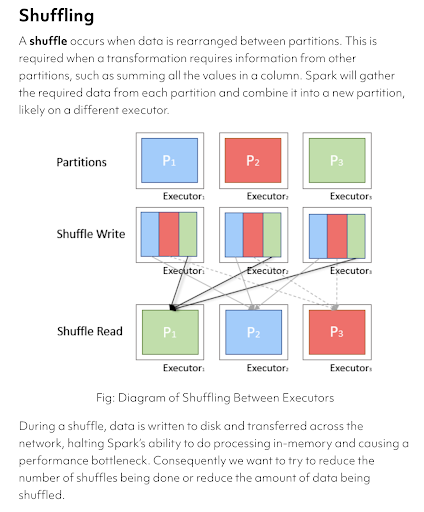
Shuffling
Spark Operations
There are 2 kind of operations available in Apache Spark
Transformations
Transformations are lazy operations which usually create or transform the data in one or other way. For example:
a) range (1,10) transformation creates a dataset of 10 variables ranging from 0 to 9.
b) filter(x > 10) will return all variables greater than 10 from the dataset by the name x.
Transformations themselves are of two types:
a) Narrow Transformations: These transformations do not entail any network communication (e.g. range and filter transformations)
b) Wide Transformations: These transformations do entail network communication (e.g. groupBy, joins, repartition). Wide Transformations usually result in redistributing data across partitions (also known as shuffling of data, section below)). Redistribution is defining behaviour in wide transformations.For example, a
groupByredistributes data across partitions by the key on which grouping is needed. Ajoinredistributes data across partitions to match joining keys.Actions
Actions in Spark are eager operations that trigger the execution of logic. For example, a
countaction triggers a job to count the number of variable created or present in a dataset. Acollectcollects all the data from the partitions and returns some output. Actions are usually written towards the end of your code after all the transformations are completed.
Shuffles in Spark
Wide operations within Spark trigger an event known as the shuffle. The shuffle is Spark’s mechanism for redistribution. This typically involves copying data across executors and machines, making the shuffle a complex and costly operation and should be avoided as much as possible, unless it is absolutely necessary.
Operations that create a shuffle
Shuffles in Spark usually come into the picture when a wide transformation (like groupBy, joins, repartition etc) is used in transformation logic. Let us take the example of a groupBy transformation to understand this better. Spark programs usually read the data in the form of in-memory partitions. The data in these partitions is distributed across different machines on the cluster and is by default not grouped on a particular field. If we apply groupBy on a certain field like country for example, the Spark runtime will have to shuffle the data across the initial in-memory partitions to make sure that all the data from the same country moves to the same partition.
Acceptable Shuffles and Avoiding Shuffles
As you might have guessed by now, shuffling is a necessary evil, especially for wide transformations in Spark. A data shuffle happens if we are using transformations like groupBy, joins and repartition. Since shuffles are expensive, the best way to avoid them would be to:
- write your logic using narrow transformations like map, flatmaps and filter.
- use wide transformations only when required and no other alternative is available in narrow transformations.
- use wide transformations as late as possible or towards the end of your logic (e.g.join only at the end of your logic)
Resources (Bonus)

- Spark DAGs and planning (optional)
- Just know that bad partitioning → shuffling → pain (must-watch)
- You can check how ‘shuffly’ your Spark job looks by viewing the DAG
- Managing Partitioning
- Important: understand that repartition() and DataFrame.write.partitionBy() are not the same thing
- Repartition can take in 2 different types of arguments:
- a number: controls the number of .snappy.parquet files
- a bunch of column names: it will ensure 1 .snappy.parquet file per each distinct combination of your provided columns
- DataFrame.write.partitionBy defines the folder structure of the table
- however, it does not guarantee how many .snappy.parquet files will be in each folder
- Sometimes you might even need to do both e.g.
df.repartition(“year”, “month”).write.partitionBy(“year”, ”month”)...in order to guarantee exactly 1 .snappy.parquet file per each month folder
- Repartition can take in 2 different types of arguments:
- Try to read up on the difference between repartition and coalesce
- Short Answer: The coalesce transformation applied to a DataFrame (not to be confused with coalesce() applied to a column), will try to merge partitions to reach your desired number. You only use coalesce when you want to reduce the number of partitions in your data.
- On the other hand, repartition() will full shuffle all of the data around (more expensive).
- If you need to increase the number of partitions in your data, then you will need repartition()
- Important: understand that repartition() and DataFrame.write.partitionBy() are not the same thing
Note - If not done already, it will be a good idea to revise the repartitioning and partition by videos from here before attempting the below exercise
Follow the instructions here to import the repartitioning exercise notebook