This section takes about 2h20m to complete.


Data Milky Way: A Brief History (Part 2) - Evolution
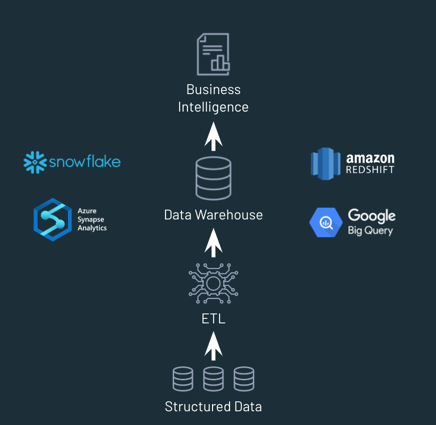
1980s: Databases & Data Warehouses
Since the 1980s up until the mid-late 2000s, businesses still stored both OLTP and OLAP data in relational databases (RDBMS)
e.g. Oracle, Microsoft SQL Server, MySQL, PostgreSQL, etc.
OLAP-oriented databases for storing large amounts of data were called Data Warehouses
Relational databases were notoriously difficult to distribute/scale out
As more data came in, businesses often opted to scale up 💰 (scale up vs scale out)
- Greater investment risk, difficult to plan capacity, expensive
- Restrictive limits to CPU & memory for a single server
- Nowadays, modern Massively Parallel Processing (MPP) warehouses can provide scale out capabilities
However, Data Warehouses still require careful upfront planning
- Schema and layout need to be decided beforehand
- Query patterns/use-cases needed to be preempted
- Separation of storage and compute often a weakness (perhaps except for modern warehouses such as Google BigQuery and Snowflake)
Data Warehouses
Pros
- Good for Business Intelligence (BI) applications (structured data, so long as it isn't too massive)
Cons
- Limited support for advanced analytics & machine learning workloads
- Limited support for non-tabular, unstructured data (e.g. free text, images)
- Proprietary systems with only a SQL interface
Because of the limitations around flexibility and scaling, a new technology emerged in the early 2000s.
Early 2000s: Hadoop Hype Train
Arrival of On-Prem Data Lakes (2004) Google published the MapReduce whitepaper, inspiring the Apache Hadoop project
- enabled (on-prem) distributed data processing on commodity (cheap) hardware
- businesses began throwing data into their Hadoop clusters!

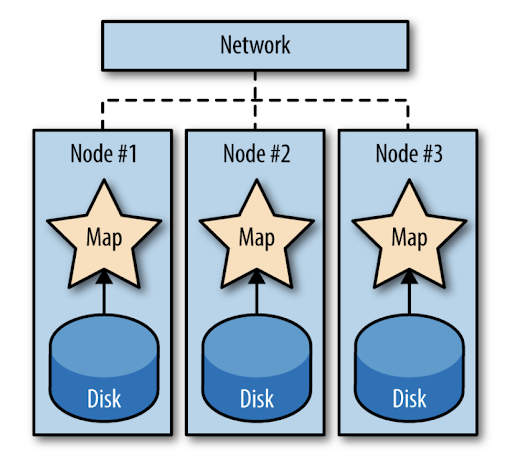
Bonus content: What you need to know about Hadoop (Very detailed and not required for the remainder of the course!)
The Hadoop Disillusionment
Several years later, people became disillusioned about Hadoop:

Working with distributed computing can be extremely challenging with respect to the learning curve, especially for business analysts. Instead of working with SQL, they'd have to learn Java libraries and frameworks related to MapReduce.
Excerpt:
Hadoop is great if you're a data scientist who knows how to code in MapReduce or Pig, Johnson says, but as you go higher up the stack, the abstraction layers have mostly failed to deliver on the promise of enabling business analystics to get at the data.
In addition to the learning curve, the performance was surprisingly slow for BI users. They would have expected that compared to the warehouse, they would have had performance gains but in fact the queries were running a lot slower on hadoop than on the traditional data warehouses.
Excerpt:
"At the Hive layer, it's kind of OK. But people think they're going to use Hadoop for data warehouse...are pretty surprised that this hot new technology is 10x slower than what they're using before," Johnson says.
This disillusionment led to the sunsetting of Hadoop projects, including at Google (who were the inventors of the entire ecossystem).
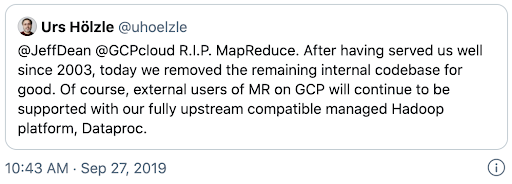
Senior Vice President of Technical Infrastructure, Google
While data locality + coupling storage and compute in Hadoop clusters was a decent idea for data throughput…
- Businesses were forced to increase both CPU & Disk when they often only needed to scale up just one or the other
- You’d have to pay for more CPU just to store inactive, rarely-utilized data, what a waste!
- Storing and replicating data on HDFS (Hadoop Distributed File System) was expensive and difficult to maintain
- Query performance was lackluster and other beneficial properties of RDBMS were gone
Latency
Latency nightmare when only using disk and network (i.e. MapReduce). Let's get a feel for it relative to "humanized" time.
| Type | Time | Time (humanized form) |
|---|---|---|
| 1 CPU Cycle | 0.3 ns | 1 s |
| Level 1 Cache Access | 0.9 ns | 3 s |
| Level 2 Cache Access | 2.8 ns | 9 s |
| Level 3 Cache Access | 12.9 ns | 43 s |
| Main Memory Access | 120 ns | 6 min |
| Solid-state disk I/O | 50 - 150 µs | 2 - 6 days |
| Rotational disk I/O | 1 - 10 ms | 1 - 12 months |
| Internet: SF to NYC | 40 ms | 4 years |
| Internet: SF to Australia | 183 ms | 19 years |
| OS Virtualization reboot | 4 s | 23 years |
| SCSI command time-out | 30 s | 3000 years |
| Hardware Virtualization reboot | 40 s | 4000 years |
| Physical System reboot | 5 m | 32 millenia |
Latency matters in Hadoop
Hadoop is all about fault tolerance and simple api of map and reduce steps. But all that fault tolerance in Hadoop comes at a very huge cost:
- To recover from potential failures, Hadoop MapReduce writes intermediate data between Map and Reduce steps to the disk for every job.
- The MapReduce implementation in Hadoop, by design, shuffles the data between map and reduce steps, which is expensive.
Now looking at the above table, we know that writing to the disk and network communications are slow and expensive and quite naturally increases latency. Because of the inherent behavior of MapReduce (constant data transmissions and persisting), attention must be paid to the amount of data that gets transmitted to manage both speed and costs of queries.
Spark is pre-built to reduce latency
Spark also provides fault tolerance like Hadoop but with significantly reduced latency in the following way :
- It keeps all data immutable and in memory, thus avoiding disk writes, by keeping data in memory.
- It provides Scala like chains of operations (called transformations) and keeps track of it in its light weight client side process called as Spark Driver.
- In the event of a node failure, it finds a new node, copies the partition data on that node and just simply plays the tracked operations in step 2 above.
Additionally Spark provides rich APIs in Scala, Python, Java and R. Lastly, unlike hadoop, it makes data shuffle optional by making it necessary only when using certain spark operations (formally called wide transformations in Spark) like joins, groupBy etc.
Optional content: 24 minute video version of Latency in Big Data (demonstrates the massive impact of using memory vs disk vs network in Big Data):
Cloud Revolution
Cloud Revolution: Why object storage wins over Hadoop-based storage
- To scale cost-effectively, we need to really separate compute and storage
- e.g. simply provision more CPU-intensive clusters only when needed, while leaving storage the same
- As analytics and AI began to involve images, audio, unstructured data:
- Cloud Data Lakes (often based on object storage) became the ideal storage solution
Time for unified analytics/query engines such as Spark and Presto to shine 💫
- Spark & Presto
- Both engines excel when running analytical queries against data stored on Object Storage (e.g. Amazon S3, Azure Blob Storage)
- Both engines take advantage of both memory and disk (unlike Hadoop MapReduce which read/writes data via disk only)
Spark (much more on this later) is extremely popular for programmatic (Python/Scala/Java/R) use-cases but can also support SQL queries.
Presto is a popular choice for ad-hoc interactive SQL queries (e.g. AWS Athena is a serverless offering based on Presto).
Many companies (especially tech giants) can even often have both Spark and Presto/Athena in their stack:

Unified Analytics Engines
Both Spark and Presto can be considered Unified Analytics Engines, meaning they can cover most of your data needs from ingestion from different sources over transformation to visualisations. What's special is that this multi-purpose approach enables you to adjust the technologies to your needs (and the arrangement of your data) and not vice versa.
Mission Accomplished?
While being able to directly query your cloud object storage (e.g. S3, Azure Data Lake Storage) with big data engines such as Spark and Presto moved the field in a great direction, some missing pieces still remained. Let's have a look at the setup of traditional data lakes versus more versatile solutions.
2000s - 2010s: Traditional Data Lakes
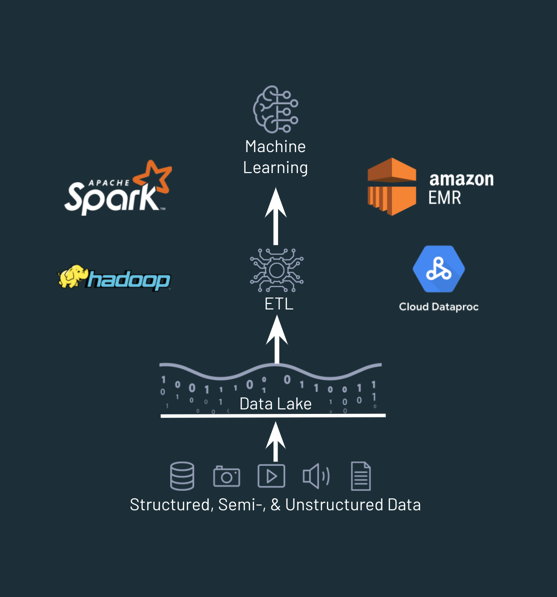
Pros
- Extremely cheap and scalable
- Open, arbitrary data formats and big ecosystem
- Supports ML
Cons
- Some BI workloads still not snappy enough
- Complex data quality problems
- No data management layer
- Difficult for GDPR compliance
Can we get the best of both worlds?
The goal in this space is to get rid of the current shortcomings listed above. We want to continue to use cheap and scalable computing resources and a wide ecosystem while being able to tackle more advanced problems, opening up data related problems to entire companies while maintaining appropriate data security and access policies.
One approach is the so-called Data Lakehouse which we’ll revisit in the second week of the course.
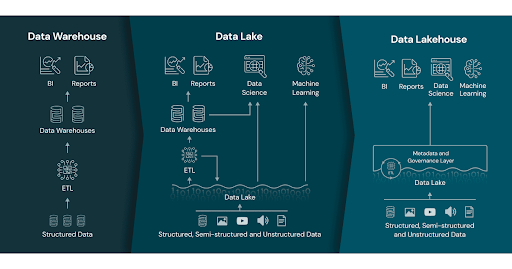
Other challengers in this area are Delta Lake, Dremio or Databricks Photon. We’ll also cover how Lakehouse can serve as the technological foundation to support philosophies such as Data Mesh near the end of this course.