🕑Estimated time for completion
This section takes about 15 minutes to complete.

Curator
Paradigm Shifts
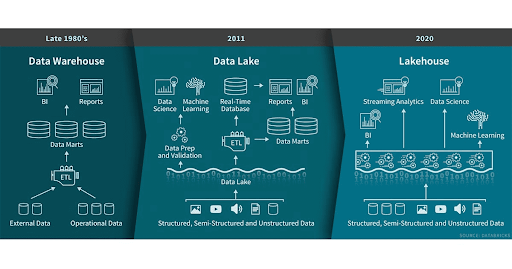
History of Big Data - Revisited
- Databases
- single node servers, vertical scaling only
- mostly used for operational data, transactions
- On-Prem Data Warehouses
- horizontal scaling possible
- utilized massively parallel processing (MPP) to run big queries
- SQL-only interface, low interoperability
- On-Prem Data Lakes
- Hadoop ecosystem
- Data Processing via MapReduce, Hive, Spark, etc.
- Difficult for data governance and data integrity
Cloud Big Data Paradigms
Cloud Data Warehouses




Pros:
- [For Snowflake and BigQuery] Decoupled storage and compute
- Excellent for BI, Reporting, Dashboarding
Cons
- Your data gets locked away in a proprietary data format
- SQL only, limited programmatic support (often needed for ML/AI use-cases)
- Limited support for unstructured data (e.g. text, images, audio, video)
(Vanilla) Cloud Data Lakes




Pros
- Decoupled storage, compute, and data
- Open, interoperable data formats (e.g. Parquet)
- Supports unstructured data
- Enables highly scalable ML/AI use-cases
Cons
- Can be susceptible to poor data quality/integrity
- Not as fast as a database/data warehouse for interactive needs (e.g. dashboards with several drilldowns/complex queries)
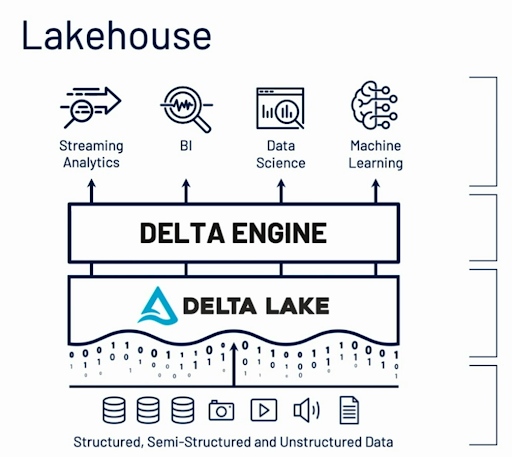
Can we get the best of both worlds?
...enter the Data Lakehouse
Source: Databricks
Example Lakehouse Contenders
Databricks
- Webpage - Demo Hub
- Photon engine: taking advantage of modern hardware with C++
- Delta Lake scalable, efficient open format on the lake but with ACID capabilities and data reliability
- Databricks SQL:
- Takes advantage of Delta Lake for data integrity
- Photon for fast, interactive queries
Dremio
- Webpage
- Utilizes Apache Arrow for scalable data transfer and serialization
- Informally, think of it as next-gen Presto/Athena (SQL Engine for directly querying the lake)
The Cloud Providers AWS: Glue Ecosystem, Athena, Lake Formation, etc. Azure: Azure Databricks, Azure Synapse Ecosystem, etc.
Takeaways
Big Data technologies/architectures such as Lakehouse are rapidly maturing to support the needs of Data Mesh