This section takes about 30 minutes to complete.

Common Landmarks of Data Processing
Once the scope of a Data Product has been defined and it is clear what question is to be answered and the data requirements (accuracy, freshness, etc) have been defined, we can start to think about the steps in Data Processing. It is necessary to understand the scope and requirements because it will help us understand what types of tech and processing that is required. For example, if the data is required to be near-real time, we might choose to transform less (saves time) and use streaming technologies. If the data is required to be processed once per month, we might choose to batch process our data (saves money).
Regardless of whether or not we are doing batch processing or streaming, there are a few landmarks which we can look out for in the world of data processing.
- Data Source
- Ingestion
- Transformation
- Intelligence
- Visualisation
- Decisions and Actions
Data Source
This is the source of data. For many of our Data Engineering use cases, it is often data that is generated as a result of a transactional application (e.g. e-commerce application) and stored in a database that fits the transactional application's usecase. This could be a Postgres or mysql database, IoT devices, json/csv files, or another data format as a result of previous processing.
There's also plenty of open source datasets as well:
- Our World in Data
- NASA Data
- NYC Taxis
- Open Movie Database
- Reddit Corpus
- Physical Characteristics of Abalone
- MNIST Database of Handwritten Digits
- Transcripts of all Friends (TV Show) episodes
Some important questions to ask yourself when selecting a data source are:
- Does it come from a reputable source? Was the data collected in a trustworthy and responsible fashion?
- Is the data biased? Does it omit key information?
- Is it too curated for what you need? (e.g. rounding, sampling)
- Do you understand how the data was aggregated and how it might affect your conclusions?
- Do you understand the domain and what each data point represents?
Ingestion
This step is the action of reading from the data source. In batch processing, we often read or ingest data as-is or close to as-is so that it allows us to debug or reprocess data in case of pipeline/processing failures. In streaming, we read directly from a stream, like a Kafka Topic or AWS Kinesis Stream.
Transformation
Once the data has been ingested, transformation logic aggregates and shapes the data into a form that can be easily understood and analysed, or used downstream in another pipeline. In batch processing, we sometimes see this in the form of Bronze, Silver, Gold stages (called "multi-hop" architecture) which represent increasingly curated levels of data. While they're a helpful guideline, it's not required to use the Bronze, Silver, and Gold multi-hop architecture strictly - sometimes it is enough to think through your problem and determine relevant and pragmatic stages from there.
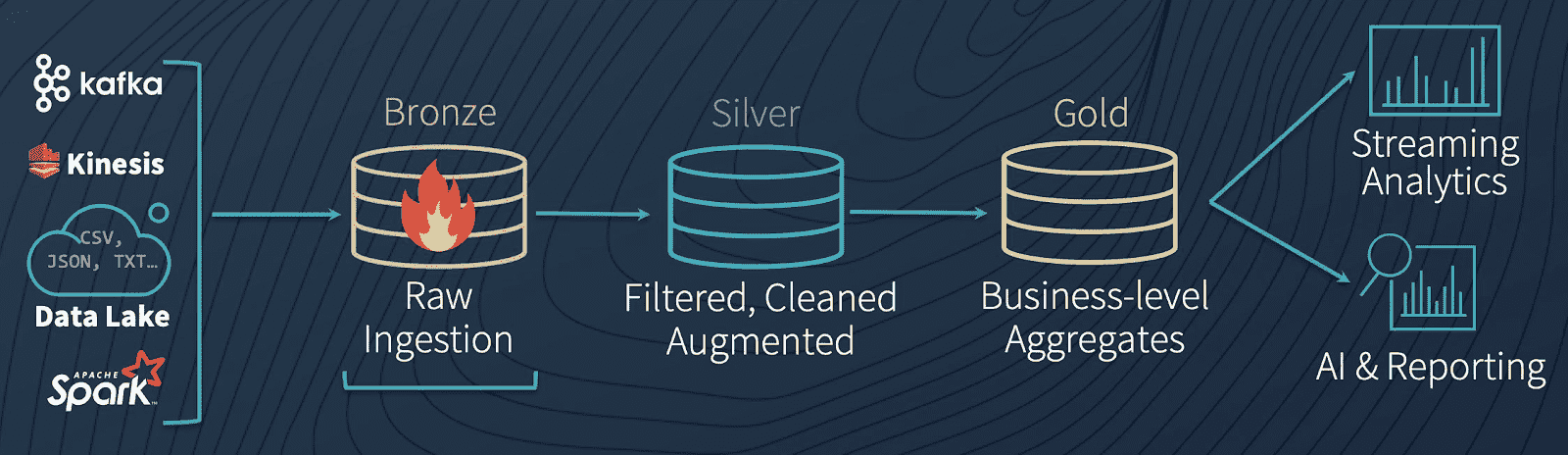
In this space, we typically work with data frames (think: spreadsheets with columns and many rows that could be turned into a CSV file, but way cooler than spreadsheets 😎) and transform them using a SQL-like language and (if needed) distributed compute like Spark (for handling large amounts of data quickly). This part requires some deeper knowledge of SQL.
Visualisation
Typically, we spend quite some energy in the Ingestion/Transformation space to get the data into a specific shape but we mustn't forget about why we ingested/transformed data in the first place: to give transparency and insights into a system in order to make an informed decision or opinion. Visualisations is just one form of how we use data to bring value to a consumer and can come in the form of a graph/charts or list of data. Different forms of visualisations are deemed appropriate in efficiently communicating different kinds of messages.
Some examples:
- Line graph to show linear trends
- Scatter plot to show the relationship between variables to determine a positive or negative correlation
- Histogram to show the distribution of numerical data
- Box (and whisker) plots to show the spread and skewness of data
- Log Chart, a non-linear method to display rapidly-growing values (e.g. exponential values) in a small graph
Some types of charts like bar plots can hide or misrepresent the spread of data.
Intelligence
Another consumer of curated data are Intelligence applications. This could be a Machine Learning model which uses analytical/curated data as training data which could drive a recommendation engine in e-commerce or streaming media systems. Often, Machine Learning models require lots of [relevant] data for training and a different set of data for testing the model and work with Data Engineers to obtain the right kind of data. Sometimes a Data Scientist or Machine Learning Engineer will simply request "all the raw data" if the data is too well curated or aggregated but in reality, this is really just the start of a conversation and strong collaboration between a ML Engineer and a Data Engineer to leverage the best of the toolsets between the two expertises (e.g. distributed data processing engines, MLOps tooling). What's exciting about Intelligence applications is that it doesn't just inform a business decision but also has the ability to feed back into Customer-facing applications (for example, recommendation engines).
In this training, we won't build our own ML model, but will describe the ML process in a later section since Data Engineers might be in the position to supply data to ML Engineers and understanding the kinds of questions that ML Engineers answer will influence the design of upstream data systems maintained by Data Engineers.
Decisions and Actions
The end goal of any Data Product should be to help a consumer / business to make an informed data-led decision. We called this Augmented Decisions and that Decision should be auditable and trackable. Another type of Decision is a "Machine-Led Decision" which is an automated decision based on data input (for example, a change in status triggers a certain automated downstream behaviour). Sometimes, a valid output of a Data Product is a dashboard, but dashboards are often thrown over the wall and not looked at. If we cannot reliably inform a downstream decision or action, a Data Product does not have purpose or value, which is why constant revalidation of models or other Data Product outputs is necessary.
Bonus: Intelligent Enterprises
If you're wanting to understand the various levels of maturity in an enterprise, check out the Intelligent Enterprises series.