🕑Estimated time for completion
This section takes about 10 minutes to complete.

Curator

Curator
Stateful Streaming in a Nutshell
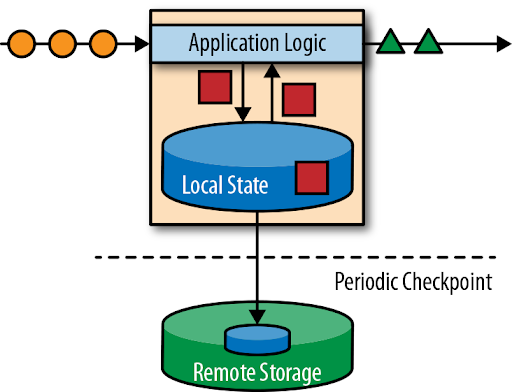
We have come a long way, haven't we? We started with learning the basics of Streaming as a concept. We then moved on to Spark Structured Streaming and appreciated its similarities with Spark SQL with the help of a few examples. Next, we differentiated between Stateless and Stateful programs and lastly, how to handle late data using windows aggregations and fault tolerance through checkpointing.
To summarise, we may use some or all of the above topics in our applications but the typical elements of a Spark Streaming Application would look like this:
- Streaming Source (production-grade applications typically use Apache Kafka or a similar technology)
- Spark Streaming Application (Stateless or Stateful, depending upon the use case)
- Checkpointing for Fault Tolerance
- Output Sink (production-grade applications will dump the data into a data store to be picked up by the end users of this data)
- End Users of Data (Tableau, Matplotlib, ML Pipelines, etc) pick up the near real-time data to drive insights or other products requiring near-real time data