Data Milky Way: Brief History (Part 3) - Data Processing
Evolution of Data Processing
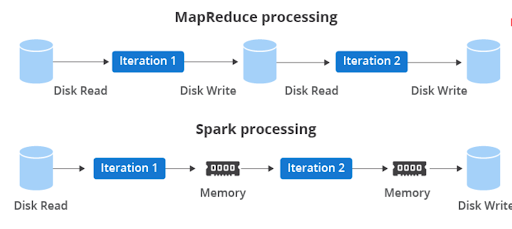
- Recap: Why move from Hadoop to Spark + Object Storage
- Intro to Metastores and Data Catalogs
- Batch and Micro-Batch Streaming
- Continuous Processing
- One syntax to rule them all?
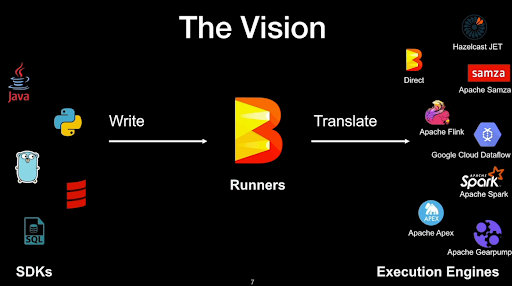
- Apache Beam is based on the Dataflow model introduced by Google
- Aims to unify the semantics of batch & streaming processing across engines (Flink, Spark, etc.)
You don’t necessarily need streaming, let alone Beam! Evaluate your own project’s needs
In my experience, most teams actually simply choose either Spark Structured Streaming or Flink (without Beam)
Orchestration Core Concepts
But how do we make our pipeline flow? 🌊
- Data Engineering workflows often involve transforming and transferring data from one place to another
- Workflows in real-life have multiple steps and stages
Sometimes, everything might work fine with just CRON jobs
However, other times, you might want to control the state transitions of these steps:
- e.g. if Step A doesn’t run properly, don’t run Step B because the data could be corrupt, instead run Step C
- Once again, the concept of Directed Acyclic Graphs (DAGs) can come to our rescue
Apache Airflow is just one nice way of setting up DAGs to orchestrate jobs 🌈
- Note: Airflow is primarily designed as a task orchestration tool
- You can trigger tasks on the Airflow cluster itself or on remote targets (e.g. AWS Fargate, Databricks, etc.)
- NOT designed for transferring large amounts of actual data
- Reference
- Play around with Airflow locally
Practical Data Workloads

We’re here to teach you big data skills, but in reality...
Single-Node vs. Cluster
Not everything is Big Data! You don’t always need Spark (sometimes Pandas deployed on a single node function/container is just fine!)
Batch vs Streaming
Streaming isn’t always the solution!
Orchestration options
DAG-based approaches: Apache Airflow, Databricks Jobs Orchestration, Dagster Event-Driven + Declarative (e.g. Databricks Auto Loader, Delta Live Tables) Other triggers: (e.g. AWS Lambda, Glue Triggers)