Data Formats
Wait...what’s data serialization again?
(extract from Devopedia)
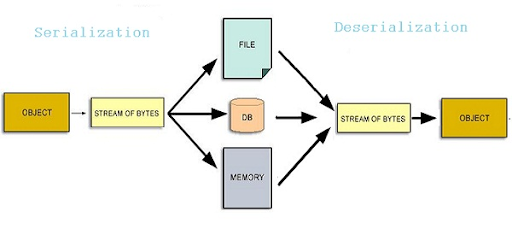
Data serialization is the process of converting data objects present in complex data structures into a byte stream for storage, transfer and distribution purposes on physical devices.
Computer systems may vary in their hardware architecture, OS, addressing mechanisms. Internal representations of data also vary accordingly in every environment/language. Storing and exchanging data between such varying environments requires a platform-and-language-neutral data format that all systems understand.
Once the serialized data is transmitted from the source machine to the destination machine, the reverse process of creating objects from the byte sequence called deserialization is carried out. Reconstructed objects are clones of the original object.
Data Formats
There are a variety of file formats common to Big Data use cases.
In this training, we’ll cover Parquet quite extensively, but Avro is a popular choice for streaming and persisting streaming data into data lakes (e.g. Azure Event Hubs Capture)
Additional Resources (optional)
A Deeper Dive into Parquet + Performance Optimisation
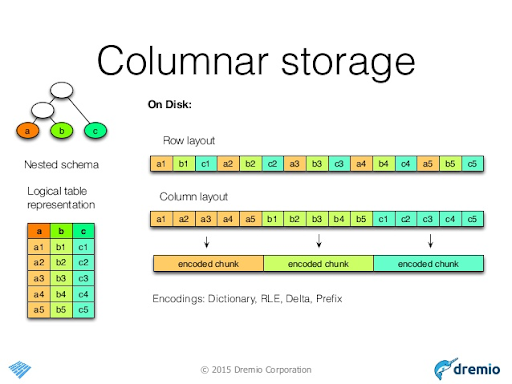
Apache Parquet Recap


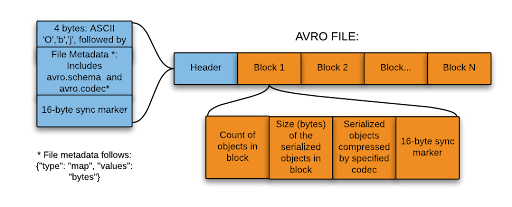
Apache Avro Recap
The only things you need to take away are that Avro files:
- are self-describing (schema accompanies data)
- are row-oriented
- support schema evolution
- are a popular serialization format for message streams
Check Your Learning!
Unlike MapReduce vs Spark, there’s no clear winner. There’s always still a time and place for each of these formats!
| CSV | JSON | Parquet | Avro | |
|---|---|---|---|---|
| Compressibility | ✅ | ✅ | ||
| Human Readability | ✅ | ✅ | ||
| Schema Evolution | ✅ | |||
| Row or Columnar Storage | ✅ | ✅ |
Bonus: Delta Lake
We'll cover Delta Lake in detail in the "Making Big Data Work" section, but let's define it here so you can keep an ear out for it. Delta Lake is an open source storage layer. It is similar to Parquet (some people refer to it as Parquet Plus) but it provides ACID transactions, time travel, the ability to remove data across various versions (vaccuuming), and you can stream and batch at the same time.