Apache Spark
Introduction to Spark
- Video from DataBricks
- First 3 minutes at least, can skim the rest
- slides from Brooke Wenig
- Video from Dustin Vannoy
Reflect
- Understand the difference between Transformations (lazy evaluation) and Actions
- Understand the difference between Driver and Worker nodes
Useful Links
- Spark SQL Programming Guide (Python or Scala recommended)
- DataFrame Methods - e.g. df.someMethod()
- Column Methods - e.g. F.col("myField").someMethod()
- The different Data Types in Spark!
- The Sacred Texts - pyspark.sql.functions
- Windows - you’re going to want to read this carefully 😉
- Campus PySpark & AWS + Spark Architectures (optional, when you have time)
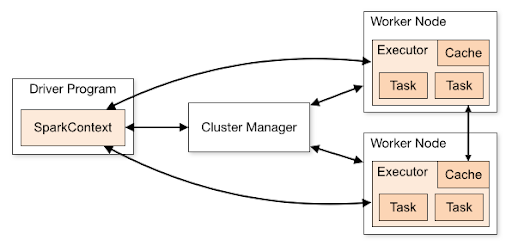
Spark Cluster Topology
Working with a distributed system can be confusing to grasp. Here are the basic must-knows:
- Very important that you understand the difference between driver and worker nodes
- Variables and data in your driver program are not automatically accessible/editable in your worker nodes
- You’ll either need to define those constants in your UDF (see Databricks exercises) or look at broadcast/accumulator variables